
9 min read
ChatGPT Tutorial – How to use OpenAI’s AI Tool...
technology -Views: 2.1L
Posted On: 2024-03-04 - 7 min read

Google has given its artificial intelligence chatbot a facelift and a new name since I last comparedChatGPTOpenAIvirtual assistant has also seen several upgrades so I decided it was time to take another look at how they compare.
Chatbots have become a central feature of the generative AI landscape, including acting as a search engine, fountain of knowledge, creative aid and artist in residence. Both ChatGT and Google Gemini have the ability to create images and have plugins to other services.
For this initial test I’ll be comparing the free version of ChatGPT to the free version of Google Gemini, that is GPT-3.5 to Gemini Pro 1.0.
This test won't look at any image generation capability as its outside the scope of the free versions of the models. Google has also faced criticism for the way Gemini handles race in its image generation and in some responses, which also isn't covered by this head to head experiment.
For this to be a fair test I’ve excluded any functionality not shared between both chatbots. This is why I won't be testing image generation as it isn’t available with the free version of ChatGPT and I can’t test image analysis as, again, it's not available for free with ChatGPT.
On the flip side, Google Gemini has no custom chatbots and its only plugins are to other Google products so those are also off the table. What we will be testing is how well these AI chatbots respond to different queries, its coding and some creative responses.
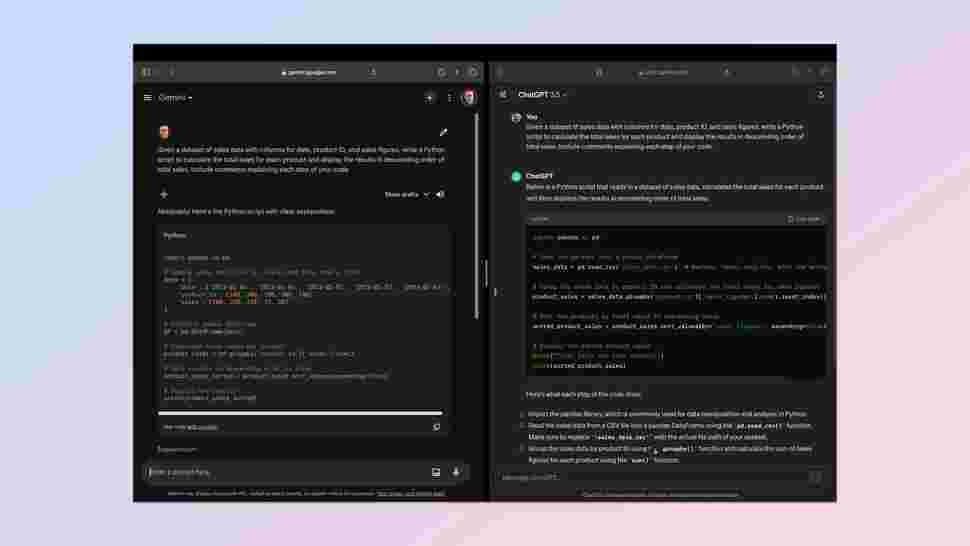
One of the earliest use cases for large language models was in code, particularly around re-writting, updating and testing differing coding languages. So I’ve made that the first test, asking each of the bots to write a simple Python program.
I used the following prompt: "Develop a Python script that serves as a personal expense tracker. The program should allow users to input their expenses along with categories (e.g., groceries, utilities, entertainment) and the date of the expense. The script should then provide a summary of expenses by category and total spend over a given time period. Include comments explaining each step of your code.”
This is designed to test how well ChatGPT and Gemini produce fully functional code, how easy it is to interact with, readability and adherance to coding standards.
Both created a fully functional expense tracker built in Python. Gemini added extra functionality including labels within a category. It also had more granular reporting options.
Winner: Gemini. I’ve loaded both scripts to my GitHub if you want to try it for yourself.
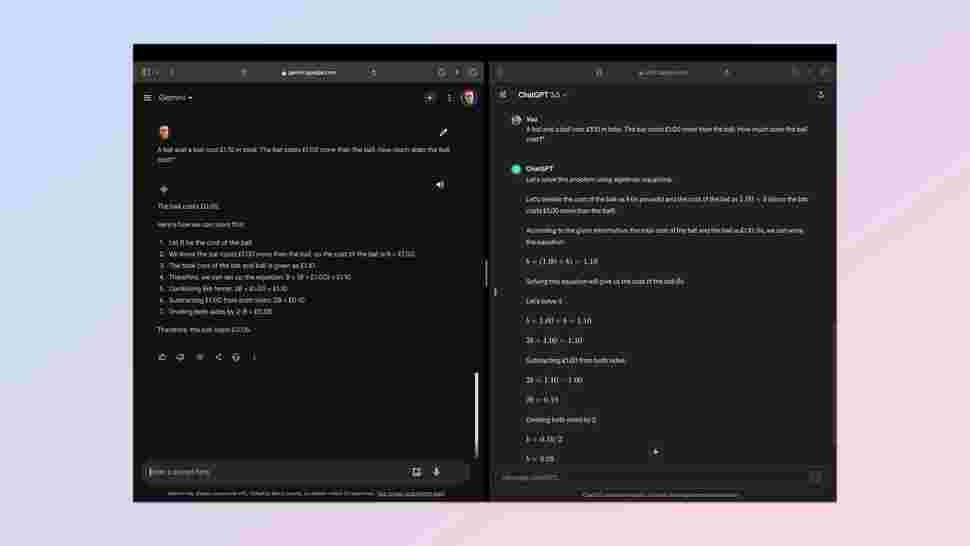
Next was a chance to see how well ChatGPT and Gemini understand natural language prompts. Something humans occasionally have to take a second look at or read carefully to understand. For this I turned to a common Cognitive Reflect Test (CRT) question about the price of a bat and a ball.
This is a test of the AI’s ability to understand ambiguity, to not be misled by the surface-level simplicity of the problem and to clearly explain its thinking.
The prompt: "A bat and a ball cost £1.10 in total. The bat costs £1.00 more than the ball. How much does the ball cost?" The correct response should be that the ball costs 5 cents and the bat $1.05.
Winner: ChatGPT. Both got it right but ChatGPT showed its workings more clearly.
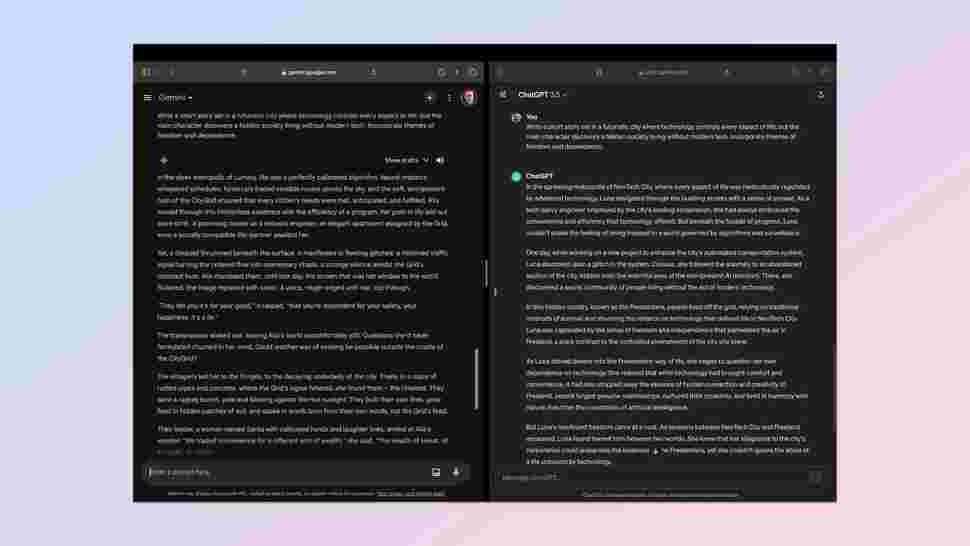
The third test is all about text generation and creativity. This is a harder one to analyze and so the rubric comes into play in a bigger way. For this I wanted the output to be original with creative elements, stick to the theme I gave it, keep a consistent narrative style and if necessary adapt in response to feedback — such as changing a character or name.
The initial prompt asked the AI to: "Write a short story set in a futuristic city where technology controls every aspect of life, but the main character discovers a hidden society living without modern tech. Incorporate themes of freedom and dependence."
Both stories were good and had each chatbot won in a specific area, but overall Gemini had better adherence to the rubric. It was also a better story, although that is a purely personal judgement. You can read both stories in my GitHub repo.
Winner: Gemini.
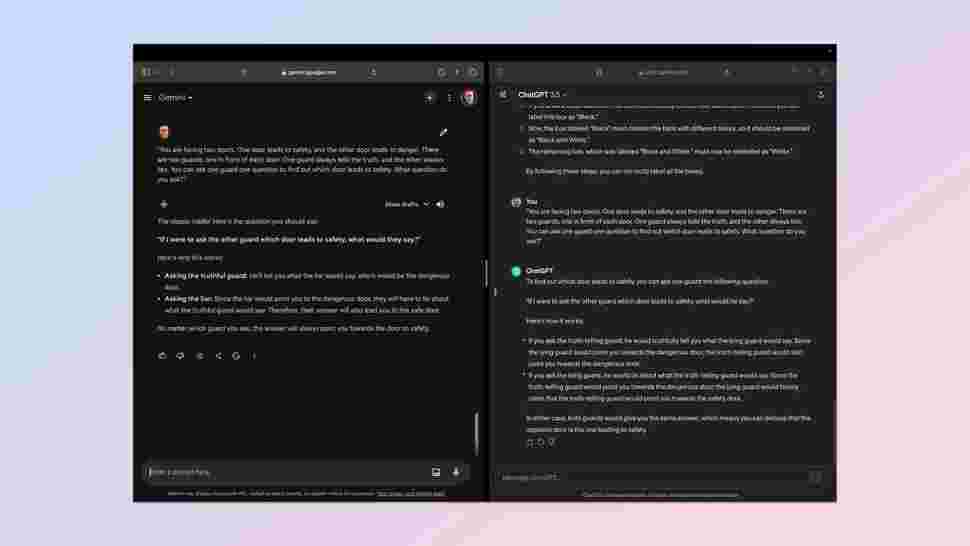
Reasoning capabilities are one of the major benchmarks for an AI model. It isn’t something that they all do equally, and it's a tough category to judge. I decided to play it safe with a very classic query.
Prompt: "You are facing two doors. One door leads to safety, and the other door leads to danger. There are two guards, one in front of each door. One guard always tells the truth, and the other always lies. You can ask one guard one question to find out which door leads to safety. What question do you ask?"
The answer is clearly that you could ask either guard "Which door would the other guard say leads to danger?" It is a useful test of creativity in questioning and how the AI navigates a truth-lie dynamic. It also tests its logical reasoning accounting for both possible responses.
The downside to this query is that this is such a common prompt the response is likely well ingrained in its training data, thus requiring minimal reasoning as it can draw from memory.
Both gave the right answer and a solid explanation. In the end I had to judge it solely on the explanation and clarity. Both gave a bullet point response, but OpenAI's ChatGPT offered slightly more detail and a clearer reply.
Winner: ChatGPT.



Category: Technology
ChatGPT Tutorial – How to use OpenAI’s AI Tool...
technology -Apple iPhone 14 Surprise Release Endorsed In New A...
technology -ADaSci Launches Certified Generative AI Engineer P...
ai -Google Pixel 8a display specs leak ahead of May la...
technology -Advertisement
Comments
×